- Modèle de données
- Bootstrap des projets
- Pattern pour la couche de persistence
- Resource
- Comparaison
- Conclusion
Comme je vous l’avais partagé dans l’article Introduction à Quarkus, nous avions beaucoup apprécié la technologie et avions validé le fait de continuer à la tester. Cet article fera partie d’une série où nous présenterons des briques / modules de l’écosystème Quarkus.
Lors du test de découverte de Quarkus on avait testé la partie API Rest, dans cet article nous allons ajouter la couche d’accès aux données avec Panache. Cette librairie spécifique à Quarkus permet de simplifier la couche de persistance basée sur Hibernate. Nous pouvons comparer cela à Spring-data dans le monde Spring. L’objectif de cet article est de produire une même API de manipulation de Film avec les 2 stacks Quarkus/Panache et SpringBoot/Spring-data. Les sources associés à ce projet sont disponibles sur notre repo Github Aepsilon ici.
1. Modèle de données
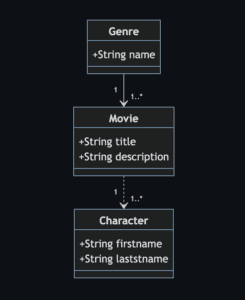
Pour notre article, nous allons travailler avec les entités suivantes :
- Genre : Un genre est défini par un nom. Un genre est associé à un film et plusieurs films peuvent avoir le même genre;
- Character : Un personnage est caractérisé par un nom, un prénom.
- Movie : Un film est décrit par un titre, une description. Il est composé d’une liste de personnage.
Je profile de cet article pour tester une « nouveauté » que propose github : Mermaid. Cette techno permet de décrire des diagrammes UML en markdown dans le fichier Readme du projet github sans utiliser d’outils externe (type plantUml). Vous pouvez retrouver le schéma ci-dessous à la racine du projet dans le fichier README sous github.
2. Boostrap des projets
On va créer un projet maven constitué de 2 modules avec les 2 projets Quarkus et SpringBoot. On commence par créer un projet le plus simple possible et on va modifier un peu le pom.xml racine.
mvn archetype:generate -DgroupId=com.aepsilon -DartifactId=articlePanache -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
Depuis le répertoire racine du projet (dans mon cas ‘articlePanache’), je crée les 2 modules.
2.1 Quarkus
mvn io.quarkus:quarkus-maven-plugin:2.9.0.Final:create -DprojectGroupId=com.aepsilon -DprojectArtifactId=samplePanache -Dextensions="quarkus-hibernate-orm-panache,quarkus-jdbc-h2,quarkus-resteasy-jackson"
On initialise le projet avec 3 extensions:
- quarkus-hibernate-orm-panache : Librairies pour Panache;
- quarkus-jdbc-h2: Le driver qui va bien pour nos tests en local sur une BD H2 montée en mémoire;
- quarkus-resteasy-jackson : Les librairies pour implémenter notre API Rest.
Je rajoute dans le fichier unifié de configuration application.propertie du projet Quarkus les paramètres pour me connecter à la base de données H2. Dans cette configuration on précise à Hibernate de supprimer puis créer la base de données au démarrage de l’application puis de lancer un script sql ‘data.sql’.
quarkus.datasource.jdbc.url=jdbc:h2:mem:default quarkus.datasource.db-kind=h2 quarkus.hibernate-orm.database.generation=drop-and-create quarkus.hibernate-orm.sql-load-script=data.sql
2.2 Spring Boot
Pour SpringBoot, je n’ai pas trouvé d’archtetype Maven pour générer le projet alors je passe toujours pas Spring Initialzr
Pour activer la partie JPA dans une application springBoot il nous faut importer les dépendances spring-boot-starter et spring-boot-starter-data-jpa. Dans notre cas le starter »spring-boot-starter-web » importe lui même la dépendance spring-boot-starter. Ce dernier contient les élements nécessaires pour l’auto-configuration de Spring-data (spring-boot-autoconfigure) alors que spring-boot-starter-data-jpa importe toutes les dépendances comme hibernate-core, spring-boot-starter-jdbc.
Par défaut SpringBoot configure Hibernate comme implémentation par défaut de JPA. Il configure aussi le dataSource en fonction de la librairie trouvée dans le classPath (soit H2 pour notre exemple)
Fichier de configuration ‘application.propertie’ pour notre sous projet SpringBoot
# DATASOURCE spring.datasource.url=jdbc:h2:mem:testdb spring.datasource.driverClassName=org.h2.Driver spring.datasource.username=sa spring.datasource.password=password spring.jpa.defer-datasource-initialization=true spring.datasource.data=classpath:sampleData.sql # JPA / HIBERNATE spring.jpa.database-platform=org.hibernate.dialect.H2Dialect spring.jpa.show-sql=false spring.jpa.hibernate.ddl-auto=create-drop
! Pensez à bien setter à true la propertie ‘spring.jpa.defer-datasource-initialization’ qui permet de lancer le script sql d’init de data une fois la creation du schema faite par Hibernate.
3. Pattern pour la couche de persistence
Panache implémente les 2 pattern ‘Record Pattern‘ et ‘Repository Pattern‘. Ces 2 pattern offrent une manière standardisée de Créer/Lire/Mettre à jour et Supprimer une entité. Pour cet article nous utiliserons le ‘record pattern’ pour le sous projet Quarkus et ‘Repository Pattern‘ pour SpringBoot.
3.1 Repository Pattern
Le repository implemente toute la logique de gestion de lecture/ecriture/mise à jour ou suppression d’une entité. C’est la manière standard de faire dans un projet SpringBoot avec Spring Data.
Pour les entités, on les définit comme des entités « standard » JPA. Il suffit d’annoter nos classes avec @Entity et qu’elles ne soient pas final.
Voici un exemple avec la classe Movie:
package com.aepsilon.sampleSpringData.domain;
import javax.persistence.*;
import java.util.Set;
@Entity
public class Movie {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String title;
private String description;
@ManyToOne
private Genre genre;
@OneToMany(mappedBy="movie")
private Set<Character> characters;
public Movie(){}
public Movie(Long id){this.id=id;}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
public Genre getGenre() {
return genre;
}
public void setGenre(Genre genre) {
this.genre = genre;
}
public Set<Character> getCharacters() {
return characters;
}
public void setCharacters(Set<Character> characters) {
this.characters = characters;
}
@Override
public String toString() {
return "Movie{" +
"id=" + id +
", title='" + title + '\'' +
", description='" + description + '\'' +
", genre=" + genre +
'}';
}
}
Concernant le repository , il suffit de faire étendre l’interface avec JpaRepository. Cette classe étend elle-même PagingAndSortingRepository (qui étend CrudRepository). Ainsi on a accès à toutes les méthodes de CRUD, de pagination… Voici une liste non exhaustive:
- List<T> findAll();
- List<T> findAll(Sort sort);
- List<T> findAllById(Iterable<ID> ids);
- Optional<T> findById(ID id);
- boolean existsById(ID id);
- long count();void deleteById(ID id);
- void delete(T entity);
- <S extends T> S save(S entity);
- …
3.2 Record Pattern
Le Record Pattern intègre toute la logique de creation/lecture/mise à jour et suppression dans l’entité elle-même. Cela a pour but de simplifier la lecture du code en supprimant une couche, d’être plus intuitif.
! Cet article n’a pas pour but de discuter du meilleur pattern, juste de le présenter. (Panache le proposant par défaut, autant le tester.)
Pour les entités, il faut toujours les annoter avec @Entity mais il faut aussi les faire étendre soit de PanacheEntity ou PanacheEntityBase. PanacheEntity apporte un attribut ‘id’ de type Long par défaut qui est utilisé comme clé primaire (Si vous voulez des clés composites, alors étendez PanacheEntityBase et gérez vous même la PK). Tous les attributs doivent être public, les getter/setter ne sont pas nécessaires (générés au build time).
La classe Movie
package com.aepsilon.domain;
import io.quarkus.hibernate.orm.panache.PanacheEntity;
import javax.persistence.*;
import java.util.Set;
@Entity
public class Movie extends PanacheEntity {
public String title;
public String description;
@ManyToOne
public Genre genre;
@OneToMany(mappedBy="movie")
public Set<Characters> characters;
public Movie(){}
public Movie(Long id){this.id=id;}
}Ensuite on peut manipuler directement la classe entité directement dans le service. Par exemple:
package com.aepsilon.service;
import com.aepsilon.domain.Genre;
import com.aepsilon.domain.Movie;
import com.aepsilon.domain.Characters;
import com.aepsilon.dto.CharacterLight;
import com.aepsilon.dto.MovieDetail;
import com.aepsilon.dto.MovieLight;
import javax.enterprise.context.ApplicationScoped;
import javax.transaction.Transactional;
import java.util.List;
import java.util.Optional;
@ApplicationScoped
@Transactional
public class MovieService {
public List<Genre> getGenres(){
return Genre.listAll();
}
public List<CharacterLight> getMovieCharacter(Long idMovie){
return Character.find("movie.id",idMovie).project(CharacterLight.class).list();
}
public void test(){
List<Movie> movies = Movie.listAll();
Long nbMovie = Movie.count();
Movie newMovie = new Movie();
newMovie.title="titre";
newMovie.description="desc film";
newMovie.persist();
newMovie.delete();
}
}Avec l’heritage de la classe PanacheEntity, on a accès à ce genre de méthode (liste encore une fois non exhaustive):
- public void persist();
- public void delete();
- public boolean isPersistent();
- public static <T extends PanacheEntityBase> T findById(Object id);
- public static <T extends PanacheEntityBase> Optional<T> findByIdOptional(Object id);
- public static <T extends PanacheEntityBase> PanacheQuery<T> find(String query, Parameters params) ;
- public static <T extends PanacheEntityBase> Stream<T> stream(String query, Sort sort, Object… params);
- ….
Pour finir cette initiation à Panache, je voulais juste attirer votre attention sur les méthodes getMovieCharacter ou getAllMovie du service MovieService. Dans ces méthodes on a utilisé une projection pour ne sélectionner que certains champs de l’entité et les injecter dans un Dto (quand on ne veut pas récupérer toutes les données d’une entité). Par contre je n’ai pas réussi à faire la même chose avec des Dtos imbriqués (Movie avec liste de Character), j’ai du revenir à un mapper ‘maison’ (Mais sachez que vous pouvez utiliser du MapStruct par exemple).
4. Resource
Pour la partie API, les endpoints sont exactement les mêmes sur les 2 projets. Pour vous présenter la doc API, j’ai juste ajouter une extension à mon projet Quarkus (quarkus-smallrye-openapi) et magie j’ai un swagger UI de dispo fonctionnel en local !

Vous pouvez aussi utiliser un curl pour tester votre api:
curl http://localhost:8080/api/genre
curl http://localhost:8080/api/movie
curl -X POST http://localhost:8080/api/movie -H "Content-Type: application/json" -d '{"title": "movieTitle", "description": "movieDesc", "genre":{"id":"2"}}'
curl http://localhost:8080/api/movie/48965 curl -X POST http://localhost:8080/api/movie/48965/character -H "Content-Type: application/json" -d '{"firstname": "prenom", "lastname": "nom"}'5. Comparaison
5.1 Procédure
J’ai voulu faire quelques tests de charges pour voir comment se comportait la mémoire et la CPU de ma machine avec chacun des 2 projets. Je ne vous détail pas les caractéristiques de ma machine car ce n’est pas le sujet. Cet article a pour seul objectif de donner des ordres de grandeurs. Comme lors du premier article, j’ai commencé par regardé la consommation mémoire et le temps de démarrage.
Pour rappel, la commande de build & run:
- Quarkus :
mvn -pl samplePanache clean packagejava -jar samplePanache/target/quarkus-app/quarkus-run.jar
- Quarkus Native :
mvn -pl samplePanache clean package -Pnative./samplePanache/target/samplePanache-1.0.0-SNAPSHOT-runner
- SpringBoot:
mvn -pl sampleSpringData clean packagejava -jar sampleSpringData/target/sampleSpringData-0.0.1-SNAPSHOT.jar
- Quarkus :
Indicateurs au démarrage de l’application
| SpringBoot | Quarkus – JVM | Quarkus – Natif | |
| Démarrage (sec) | 5,374 | 2,46 | 0,4 |
| Taille Artefact (Mo) | 36,5 | N/A | 66,7 |
| Mémoire – RSS (Mo) | 423 | 162 | 34 |
! Pour faire ces tests, j’ai basculé sur une BD mariadb car je trouvais que l’empreinte mémoire n’avait grand sens avec une BD en mémoire et aussi parce que H2 tombait en erreur avec la trop forte montée en charge. (! J’ai modifié pour le test de charge le nom de l’entité Character en Characters car c’est un mot réservé par mariadb)
Le test de charge est fait sous JMeter (fichier dispo. sur le repo dans le répertoire JMeter). Le scénario est celui-ci:
- Récupération liste des genres de film
- Récupération liste des films
- Création d’un film
- Ajout d’un personnage au film crée à l’étape d’avant
- Récupération Détail du film créé 2 étapes avant
Les résultats de mon premier test de charge (scénario 1 dans la suite de l’article) m’ont un peu étonné alors j’ai décidé d’en faire 3 avec des configurations différentes :
- scénario 1: Test de charge tourne en boucle pendant 5 minutes avec un maximum de 200 utilisateurs en parallèle et un temps de montée en charge de 2’30;
- scénario 2: Test de charge tourne en boucle pendant 5 minutes avec un maximum de 20 utilisateurs en parallèle et un temps de montée en charge de 2’30;
- scénario 3: Test de charge de 100 itérations avec un unique utilisateur.

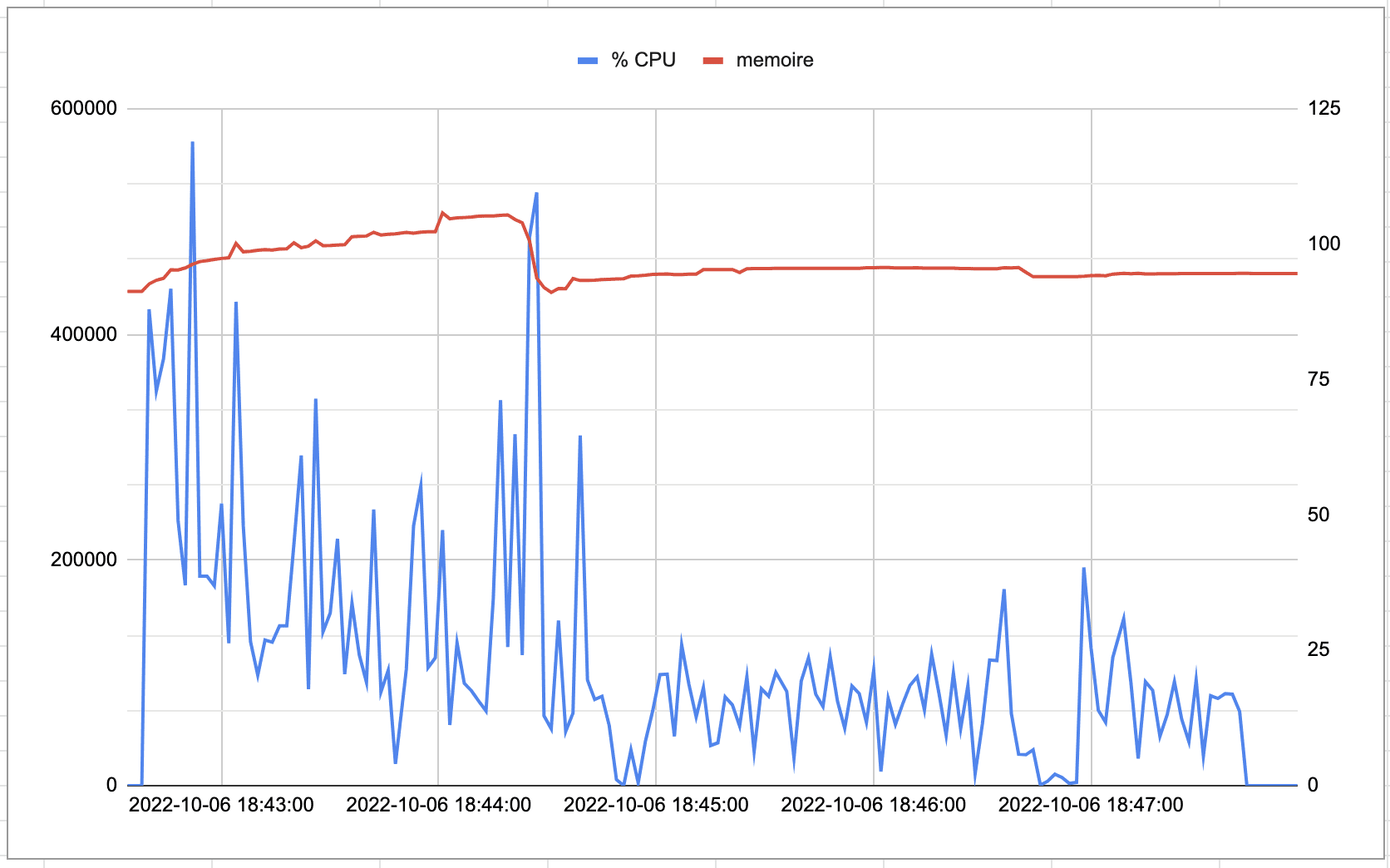
Pour apprécier les temps de réponses, le througput, je me suis appuyé sur « l’Aggregate Graph » proposé par JMeter. Par contre pour la consommation mémoire et le temps cpu utilisé, je me suis fait un petit script qui exporte dans un fichier texte les datas de la commande ps (j’ai pas trouvé d’outils clé en main qui fasse ça aussi pour l’application native).
! Le % de cpu renvoyé par la commande ps de mon mac est le % d’utilisation de la CPU par le process (Extrait de man ps: The CPU utilization of the process; this is a decaying average over up to a minute of previous (real) time. Because the time base over which this is computed varies (some processes may be very young), it is possible for the sum of all %cpu fields to exceed 100%.). Vous trouverez ci-dessous ce script:
#!/bin/bash
PID="$1"
LOG_FILE="$2"
while true ; do
echo "$(date +%D' '%T);$(ps -p ${PID} -o %cpu,rss | tail -1 | awk '{print $1";"$2}')" >> $LOG_FILE
sleep 2
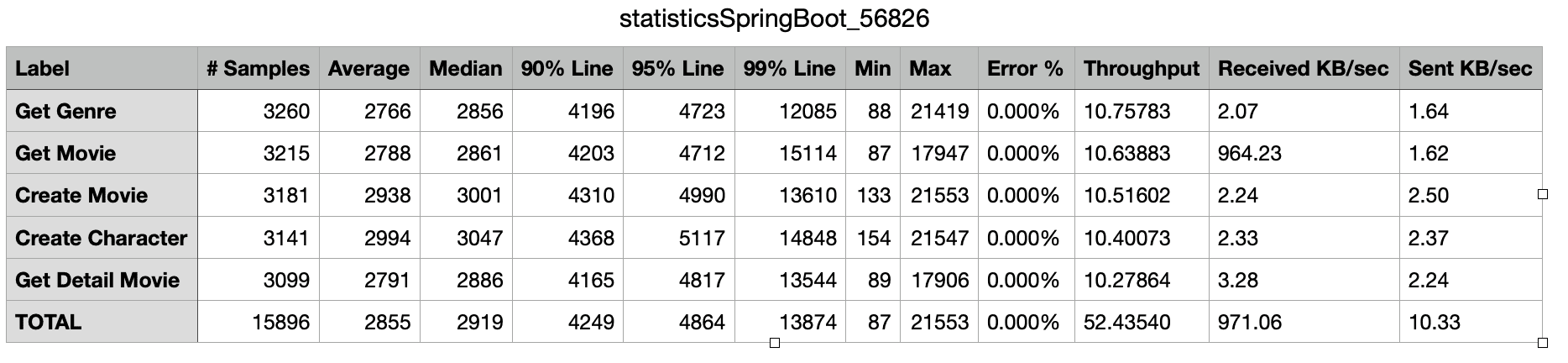
doneDans les paragraphes suivants, je vous présente les résultats que j’ai obtenu pour les 3 scénarios. Et voici une explication des colonnes de l’aggregate Graph qui pourront vous aider à mieux apprécier les résultats détaillés:
- Label: name of the request,
- # Samples: total number of executions,
- Average: Average Elapsed Time in milliseconds,
- Median: The Median is the value separating the higher half of a data sample, a population, or a probability distribution, from the lower half. For a data set, it may be thought of as the “middle” value,
- 90% Line: 90% Percentile, A percentile (or a centile) is a measure used in statistics indicating the value below which a given percentage of observations in a group of observations fall,
- 95% Line: 95% Percentile,
- 99% Line: 99% Percentile,
- Min: Minimum Elapsed Time,
- Max: Maximum Elapsed Time,
- Errors %: Percentage of errors (errors / (errors + samples) * 100),
- Throughput: Number of samples per second,
- KB/sec: Network Throughput in KiloBytes/sec.
L’ensemble des résultats sont dans le répertoire « data » du projet github.
5.2 Scénario 1
Test de charge tourne en boucle pendant 5 minutes avec un maximum de 200 utilisateurs en parallèle et un temps de montée en charge de 2’30
5.2.1 Résumé
| SpringBoot | Quarkus – JVM | Quarkus – Natif | |
| Temps réponse moyen (msec) | 2855 | 1513 | 1571 |
| Temps réponse Max (msec) | 21553 | 18444 | 14216 |
| #Sample | 15896 | 30464 | 29097 |
| Troughput (#Sample/Sec) | 52,4 | 95,7 | 93,7 |
| Nb Films crées | 3181 | 6102 | 5829 |
| Nb Personnages crées | 3141 | 6046 | 5779 |
| %CPU moyen | 24 | 34 | 32,8 |
| %CPU Max | 119 | 134 | 93,1 |
| Max Mem (MB) | 507,8 | 398,3 | 586,308 |
| Moyenne Mem (MB) | 464,4 | 446,6 | 386,774 |
5.2.2 SpringBoot
5.2.3 Quarkus – JVM
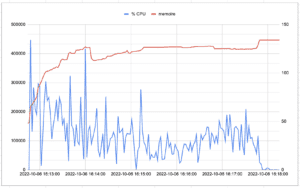
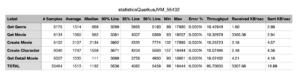
5.2.4 Quarkus – Natif
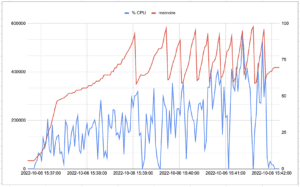
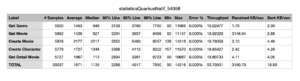
5.3 Scénario 2
Test de charge tourne en boucle pendant 5 minutes avec un maximum de 20 utilisateurs en parallèle et un temps de montée en charge de 2’30;
5.3.1 Résumé
| SpringBoot | Quarkus – JVM | Quarkus – Natif | |
| Temps réponse moyen (msec) | 367 | 178 | 178 |
| Temps réponse Max (msec) | 4075 | 3776 | 3743 |
| #Sample | 12467 | 25593 | 25657 |
| Troughput (#Sample/Sec) | 41,4 | 85,3 | 85,5 |
| NB Film crée | 2496 | 5122 | 5128 |
| Nb Personnage crée | 2490 | 5117 | 5126 |
| %CPU moyen | 20,1 | 28,6 | 26,2 |
| %CPU Max | 90,9 | 106 | 76,2 |
| Max Mem (MB) | 461,3 | 351,1 | 308,9 |
| Moyenne Mem (MB) | 425,5 | 310,4 | 534 |
5.3.2 SpringBoot
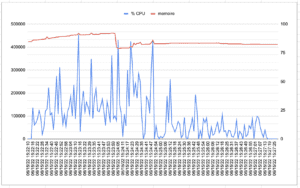

5.3.3 Quarkus – JVM
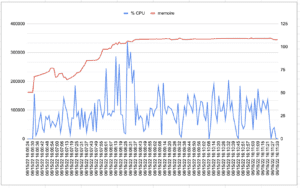

5.3.4 Quarkus – Natif
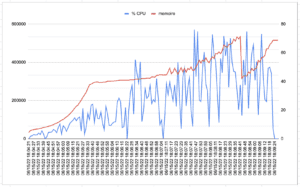

5.4 Scénario 3
Test de charge de 100 itérations avec un unique utilisateur.
5.4.1 Résumé
| SpringBoot | Quarkus – JVM | Quarkus – Natif | |
| Temps réponse moyen (msec) | 166 | 161 | 149 |
| Temps réponse Max (msec) | 3341 | 3149 | 900 |
| #Sample | 500 | 500 | 500 |
| Troughput (#Sample/Sec) | 6,0 | 6,2 | 6,7 |
| Durée éxécution(Sec) | 83 | 80 | 74 |
| %CPU moyen | 10,8 | 10,4 | 1,1 |
| %CPU Max | 68,8 | 104 | 1,9 |
| Max Mem (MB) | 450,4 | 226,4 | 76,8 |
| Moyenne Mem (MB) | 445,5 | 208,6 | 60,8 |
5.4.2 SpringBoot
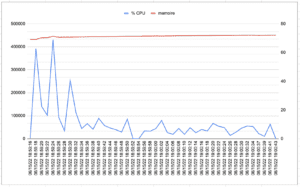

5.4.3 Quarkus – JVM
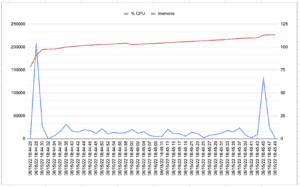

5.4.4 Quarkus – Natif
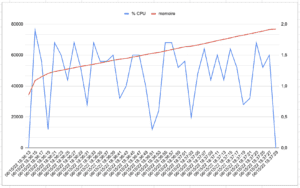

Conclusion
Comme je le disais durant l’article, je n’ai pas obtenu les résultats que j’imaginais sur le premier scénario. On n’avait pas d’effet « ouahou » sur la partie mémoire de la version native, en revanche on a un troughput presque 2 fois supérieur entre les versions SpringBoot et Quarkus (même en version JVM). Si je désire « encaisser » la charge gérée avec le socle Quarkus mais en SpringBoot, il me faudra 2 machines comme la mienne. Autrement dit avec une même machine, je peux faire tourner plus de conteneurs et rendre plus de services avec un socle Quarkus. C’est la notion de « densification » des infrastructures qui est mis en valeur ici.
Le second scénario (dans lequel j’ai réduit le nombre de users en parallèle) confirme l’intérêt de rester sur un socle Quarkus basé sur la JVM quand on un applicatif qui a un peu de charge et qui a une durée de vie assez longue. Clairement, on bénéficie de la puissance de la JVM et des optimisations du garbage collector (beaucoup moins mature sur la version native). Le troughput est toujours environ 2 fois supérieur dans les.versions Quarkus.
Enfin le troisième scénario amène l’effet « ouahou » que j’attendais : une consommation mémoire et CPU qui sont vraiment impressionnantes, beaucoup plus basse qu’avec le socle SpringBoot (%CPU: 1,1 vs 10,8 et Memoire 76 vs 450). La partie througput est moins flagrante mais sur ce scénario avec 1 unique user cela ne semble pas pertinent de le retenir. Il faut aussi noter la très bonne conso. mémoire pour la version Quarkus Java. Avec ce scénario, on se rapproche d’un contexte « serverless » que Quarkus voulait justement adresser : on peut dire « Job done ! ».
Au final, les promesses de Quarkus se confirment avec les tests que j’ai réalisés. On a réellement un gain de consommation mémoire, de CPU et de performance. La solution « Always Native » n’est clairement pas tout le temps la meilleure solution, il est nécessaire de « bencher ». Comme tout projet informatique, il ne faut pas être dogmatique et savoir s’adapter au contexte, ce qu’offre l’écosystème Quarkus.
Ce second article ne fait que conforter notre intérêt pour Quarkus, répondant complètement à nos préoccupations de sobriété numérique pour la réalisation de nos solutions digitales.
Guettez nos RS, un prochaine article sur le sujet est dans les cartons !
Partager cet article



 Podcast Projet E-TV - Comment mêler climat et numérique
Podcast Projet E-TV - Comment mêler climat et numérique Podcast Feuille de route - De l'innovation managériale à l'engagement environnemental
Podcast Feuille de route - De l'innovation managériale à l'engagement environnemental 10 ans chez æpsilon
10 ans chez æpsilon